From EC2 to AWS Managed Services: Migrating to AWS RDS with DMS
Introduction
Last week, I successfully deployed an MVP using a simple but effective setup — a custom AMI with everything bundled into a single EC2 instance. Building an MVP is just the beginning of a startup’s journey. As the user base grows, the initial infrastructure needs to scale effectively to meet the increased demands.
This week, I undertook a major infrastructure upgrade to ensure the platform remains fast, reliable, and cost-efficient as I scale by:
✅ Migrated the database from EC2 to Amazon RDS using AWS DMS
✅ Moved image storage to S3 with CloudFront for global delivery
✅ Secured configurations using SSM Parameter Store
✅ Updated the app to leverage these AWS services seamlessly
Let’s dive into the details!
Why Change the Architecture? Preparing for Growth
The initial MVP was built for speed, but scaling requires a more robust foundation. Here’s why the old setup wouldn’t work long-term:
1. More Users, More Problems
Then: A single EC2 instance handled everything (app, database, storage).
Now: Traffic spikes? Database queries slowing down? RDS decouples the database, allowing independent scaling.
2. Data Everywhere, Consistency Nowhere
Then: User uploads lived on one server — impossible to share across multiple instances.
Now: S3 acts as a single source of truth for images, accessible globally via CloudFront.
3. Security & Maintenance Headaches
Then: Secrets baked into AMIs. Changing a password? Redeploy everything.
Now: SSM Parameter Store securely manages configurations, enabling zero-downtime updates.
4. Cost Efficiency at Scale
Then: Over-provisioned EBS volumes “just in case”.
Now: Pay only for what you use with S3, and optimize database costs separately.
The Bottom Line: The new architecture isn’t just about fixing today’s issues — it’s about enabling tomorrow’s success without reengineering everything later.
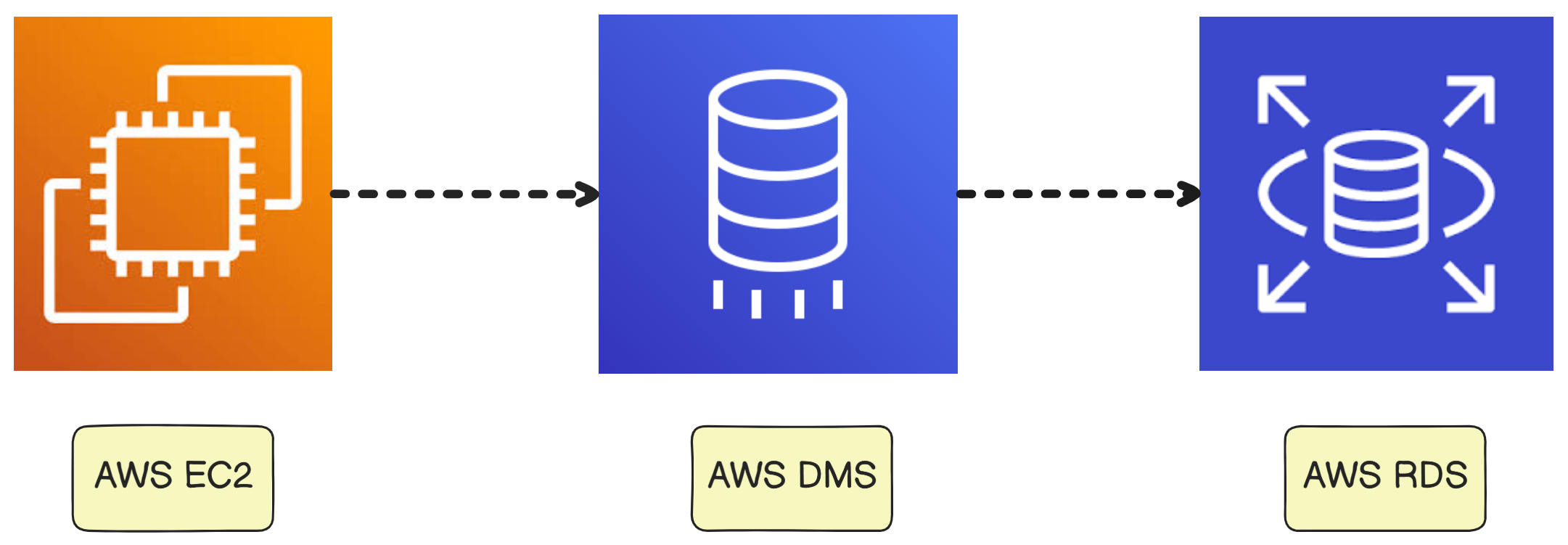
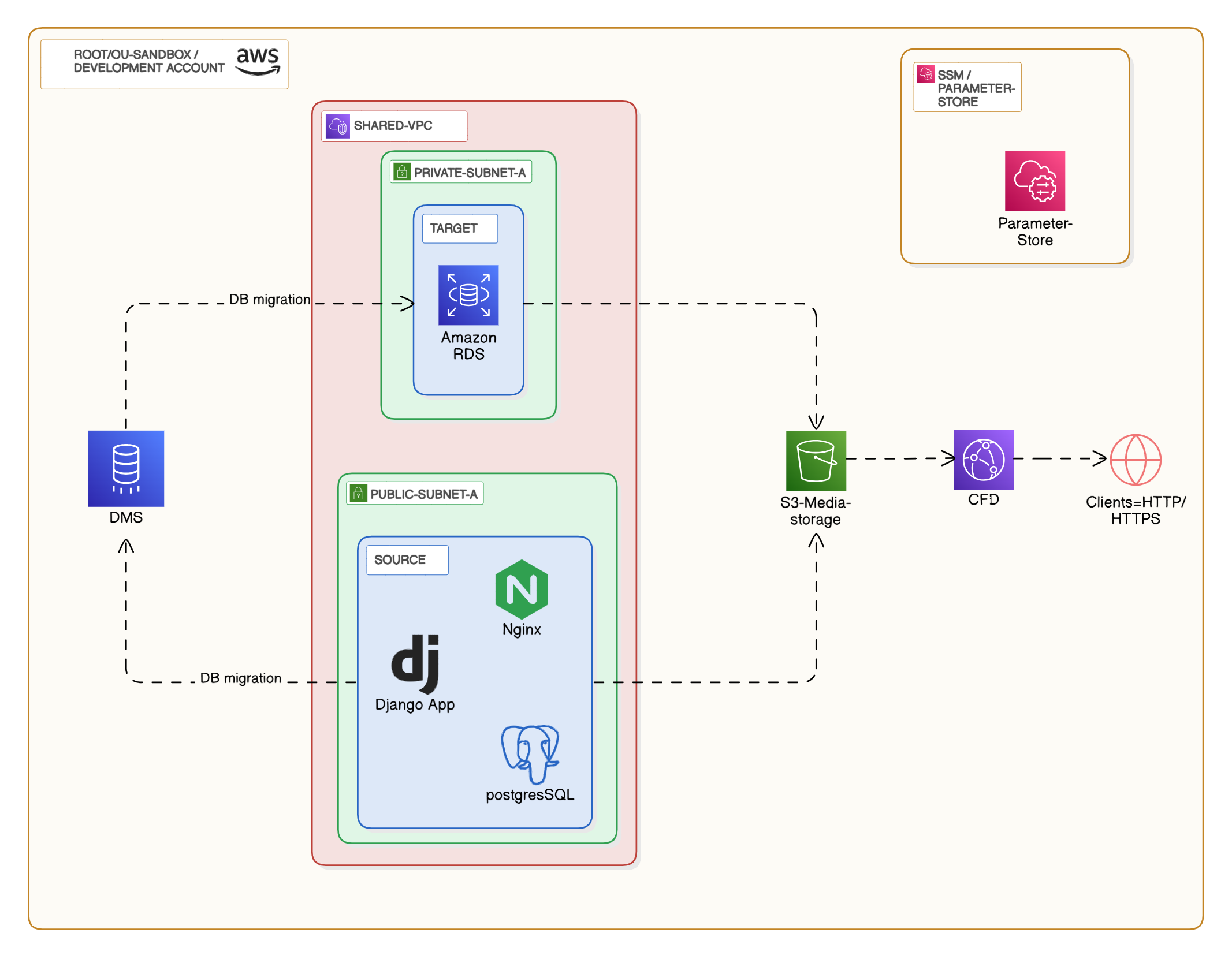
Part 1: Database Migration to Amazon RDS
Why Move from EC2 to RDS? The initial PostgreSQL-on-EC2 setup had critical flaws:
- Data loss risk (every AMI update wiped the DB)
- No horizontal scaling (only vertical, which gets expensive)
- Performance bottlenecks (DB and app competing for resources)
Why DMS Was the Right Choice? I used AWS Database Migration Service (DMS) because it enables:
- Continuous replication — Keeps RDS in sync with live EC2 database
- Near-zero downtime — Only seconds of downtime during cutover
- Automatic validation — Verifies data consistency automatically
Step-by-Step Migration with AWS DMS:
- Set up RDS PostgreSQL with Terraform
- Free-tier-friendly (db.t3.micro)
- Private subnet placement for security
- Custom parameter group to disable forced SSL (for DMS compatibility)

| |
- Configured AWS Database Migration Service (DMS) with Terraform
- Created a replication instance (dms.t3.micro)

- Defined source (EC2) and target (RDS) endpoints
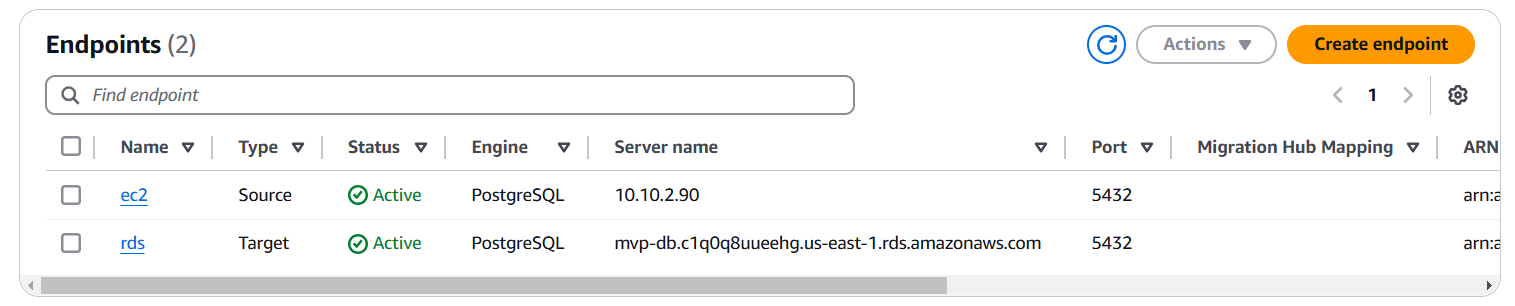
- Ran a full-load replication task to migrate data
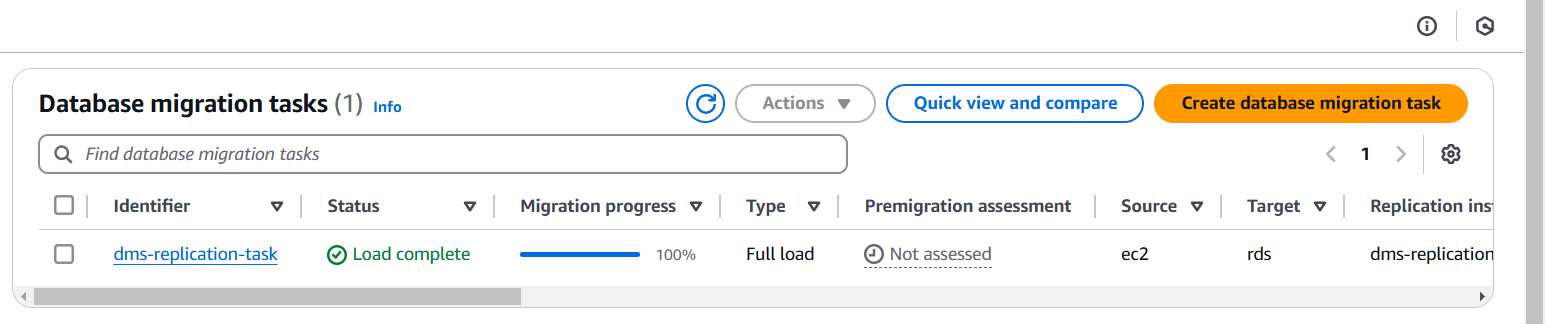
| |
- Switched the Application to RDS
- Updated Django’s settings.py to point to RDS
- Tested thoroughly before decommissioning the local DB
| |
Result: A managed, scalable database that survives instance replacements!
Part 2: Image Storage on S3 + CloudFront
Why S3 Over EBS?
- Unlimited storage (no more “disk full” errors)
- Reduced costs (pay-per-use vs. provisioned EBS)
- Global availability via CloudFront CDN
Implementation Steps:
- Created an S3 Bucket and a CloudFront Distribution using Terraform.
- Enabled Origin Access Control to ensure only CloudFront can access S3.
Updated EC2 IAM Role to grant permission for S3 operations (put, get, delete, list).
Copied existing images from EC2 to S3 using the AWS CLI as shown below.
Verified image accessibility via CloudFront.
| |
Result: Now, all user-uploaded images are stored securely in S3 and served efficiently through CloudFront, improving performance and reducing costs.
Part 3: Secure Configuration with SSM Parameter Store
Why Ditch secrets.sh?
- Hardcoded secrets in AMIs = security risk
- No audit trail for changes
- Manual updates required for credential rotation
How I Fixed It?
- Created SSM Parameters in Terraform for: Database credentials, Django secret key, RDS endpoint, S3 bucket name, CloudFront URL.
- /cloudtalents/startup/secret_key
- /cloudtalents/startup/db_user
- /cloudtalents/startup/db_password
- /cloudtalents/startup/database_endpoint
- /cloudtalents/startup/image_storage_bucket_name
- /cloudtalents/startup/image_storage_cloudfront_domain
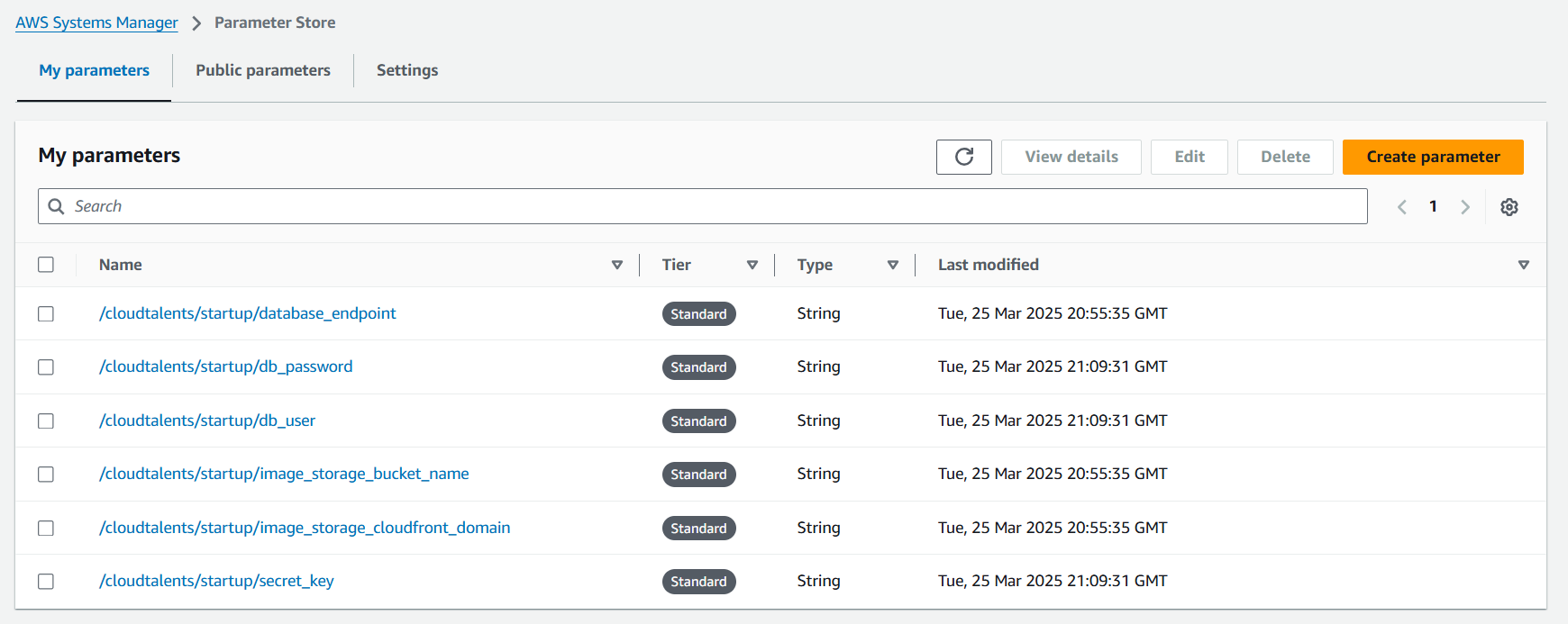
Updated EC2 Instance Profile to allow reading these parameters.
Updated GitHub Actions to remove secret file generation.
Result: No more secrets in code, and changes happen instantly across all instances.
Part 4: Deploying the New Application Version
With the new infrastructure in place, I deployed an updated version of the application:
- Replaced the application code with the new version from the provided zip file.
- Created a new GitHub release to build and deploy a fresh AMI.
- Verified the application functionality:
- Checked for previously uploaded images.
- Tested new image uploads.
Result: Everything worked smoothly, confirming a successful migration! 🎉
Challenges & Solutions
1. Server Error (500) During User Signup
Problem: The application returned 500 errors when new users attempted to sign up.
Root Cause:
- Missing auth_user table in the database
- Incorrect database credentials in settings.py
Solution:
- Updated the DATABASES configuration in settings.py to use the correct credentials.
- Ran Django migrations to create the auth_user table and restarted Gunicorn and Nginx.
| |
2. Critical File Location Issues
Problem: Django management commands failed due to missing manage.py.
Root Cause: Incorrect project structure deployment.
Solution: Reorganized files to proper locations:
| |
3. Database Migration Hurdles
Problem: DMS replication tasks failed to connect.
Root Cause: PostgreSQL security restrictions in pg_hba.conf.
Solution: Edited the pg_hba.conf file to allow connections from the DMS replication instance IP (10.10.10.215):
| |
4. Data Migration Failures
Problem: DMS tasks showed 100% completion but ended in error state.
Root Cause: Schema incompatibilities and unsupported data types.
Solution:
- Created premigration assessment report
- Modified problematic tables and data types
- Restarted migration task after fixes
Key Lessons Learned
Always Verify Project Structure Missing or misplaced files like manage.py can cause cascading failures.
Test Database Connections Early Connection issues between services should be identified before migration.
Leverage AWS Assessment Tools Premigration assessments revealed critical schema issues that would have caused data loss.
Maintain Operational Checks through regular verification of:
- Virtual environment activation
- Service status (PostgreSQL, Gunicorn, Nginx)
- File permissions
Final Thoughts
By making these improvements, the MVP is now more scalable, cost-effective, and secure:
✅ Database on Amazon RDS — No more data loss or performance bottlenecks.
✅ Images stored in Amazon S3 and served via CloudFront — Faster and cheaper image delivery.
✅ Configurations managed in SSM Parameter Store — Enhanced security and scalability.
✅ Updated application deployment pipeline — More streamlined and automated.
This upgrade ensures that the MVP is well-prepared for growth while keeping costs under control. Exciting times ahead! 🚀